In recent years we have seen significant evolutions in the technologies, design patterns, and frameworks we use to build data products. The process of extracting data from a source and making it useful in a business context is no exception. One of the biggest paradigm shifts has happened in the transition from the legacy Extract, Transform, Load (ETL) workflow to the more recent Extract, Load, Transform (ELT) approach. This evolution has also made way for another shift towards operational analytics (or “Reverse ETL” we’ll ignore the naming for now) that closes the loop by pushing data out of the warehouse and back into operational systems it came from.

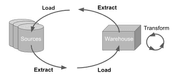
The rise and fall of ETL
ETL is a process where data is extracted from a source system (commonly an operational database), transformed on the fly to meet the needs of the data warehouse and reporting tools, and then loaded into a warehouse where it can be consumed as the final product.
One of ETL’s fundamental flaws is relying on stable and known-in-advance business requirements. Extracting, transforming, and then loading expects that the output is final. It expects that our upstream systems are stable and their stability makes our downstream systems stable too. ETL also assumes that the insights were looking for in our data are static and slowly changing. Modern data practices and business requirements have thoroughly discredited these assumptions.
Design patterns, like ETL, are conceived to solve the challenges at a particular point in time using the tools, technologies, and practices at it’s disposal. At the time that the ETL pattern gained its popularity teams were mostly limited to large enterprise tools with very expensive storage and compute cost while also following strict waterfall development cycles. With this context in mind its understandable why ETL made the most sense back then.
Times have changed. Technology has improved significantly, the cost of storage and compute have plummeted while the power and accessibility (via the cloud) of modern data warehouses have sky rocketed. These days you can turn on a cloud data warehouse and start crunching terrabytes of data in an afternoon. Development practices have also changed. Agile development cycles are more common and teams expect changing business requirements leading to many small iterative changes versus one large “big bang” release.
To iterate effectively and to adhere to modern development best practices, we needed to restructure the ETL process into its component parts (EL + T). Then we’re free to optimize each stage individually.
What is ELT and how is it different from ETL?
The transition to ELT is about decoupling workloads to optimize for faster iteration cycles. ELT is really 2 steps EL (Extract-Load) and T (Transform). The EL step is also commonly referred to as “replication” where data is extracted from source systems and loaded into a date warehouse, keeping it in raw or as-close-to raw state as possible. The T step is where data teams can use their replicas of the source system data to find insights and create business value by constantly iterating to meet ever changing business needs.
EL isn’t two things, it’s one: “replication”
Let’s start by defining what Extract-Load means in a modern DataOps platform like Meltano:
The Extract-Load (“EL”) effort represents a single unit of work: to replicate data with high fidelity, high performance, and high stability.
By reimagining Extract-Load as a standalone “data replication” system, we drastically simplify the data movement problem. Now we only really need two things: source credentials and destination credentials. All other decisions can be delegated to the EL system. The job of data replication (aka the “EL” system) is to replicate efficiently, securely, and with high fidelity.
Rather than micromanaging the replication process, built-in data replication capabilities can do 99% of the work for us. With the growth, popularity, and maturity of frameworks and specifications like Singer orchestrated by Meltano, most of the replication step is effectively commoditised. This frees us to focus only on exceptions and providing business value. For instance, rather than having 30 steps for 30 tables, we can set rules to exclude the 3-5 tables or columns that we don’t want to sync (perhaps for PII reasons). We also have fine grain control of the replication cadence based on the source system and requirements. If source data is only refreshed once a week, then we replicate on that cadence versus replicating based on the system level cadence (i.e. we want fresh reports everyday so source needs to be extracted everyday too).
In this model, we change as little as possible in the replication (EL) step, since we know we’ll have full capability to do so in the transformation layer.
So what about transformations?
As discussed above using the modern ELT pattern, the EL step can happen before business requirements are formally gathered, and with no expectation that those requirements are final because the data is kept in its raw form.
However, the opposite is true for the Transform layer of ELT. We must assume that business requirements will change over time and those changes will affect the way we transform data. If the business is healthy, the questions we ask of our data and the insights were looking for will be constantly evolving. The goal with the transformation step is to iterate and evolve forward while minimizing development time and impact of changes. Especially with the adoption of frameworks like dbt used for transforming data using SQL, teams are iterating faster and have more confidence in their changes. Transformation can happen continuously and confidently, without fear of downstream breakage.
Since we are never “done” with data transformations, we need to optimize the transformation system for efficiency of iteration. With this faster way of iterating, teams have the new challenge of balancing speed and stability to preserve trust while still providing constant improvements. This is where the value of adopting DataOps practices shines. It encourages data teams to onboard software engineering best practice, customized for the data stack, to improve the way they develop, test, and deploy their code.

Operational Analytics (Reverse ETL)
As teams have started to adopt the ELT pattern and the modern data stack, they’ve been able to unlock insights from their data that weren’t available before. So much so that theres been a recent movement to start viewing the data warehouse as not just a reporting tool but as an operational data store. Teams have generated so much value from their data that they want to start pushing those data points back into the operational systems the business depends on.
This is valuable because data warehouses are the central repository for data across the entire business and they have a global view, whereas a single operational data store only has a view of its own domain. A common use case is for generating an enterprise view of a customer. Businesses have so many data silos with individual views of a customer but until they’re all combined in the warehouse, the true understanding of that customer and their value to the business is fragmented and incomplete.
Operational analytics or what some people are calling reverse ETL is the process of taking those global views of data and pushing them back out to each individual operational data store where they can be used in normal business processes. This effectively closes the loop that ELT was leaving open by updating the very systems that it replicated data from in the first place.
The promise of operational analytics is huge but it comes with some major challenges, requirements, and expectations that aren’t easily solved yet. The quality, reliability, and governance of your data has always been very important but its taken to a new level when operational analytics is added to the mix. In order for businesses to have the same level of confidence in their data products as they have for their software products, they need to adopt DataOps practices and bring the rigor of software engineering to data. Things like data pipelines as code, versioning, code reviews, continuous integration (CI) testing, isolated testing environments, automated deploys, data quality checks, observability, and alerting. These are not easy or obvious practices to implement in the data space, that’s where Meltano can help!
How the Meltano DataOps OS can help
New patterns and development practices require new tools built to support them and the movement to DataOps is no different, thats why we’re building Meltano as the foundation of every team’s ideal data stack.
Replication and Reverse ETL: Meltano has EL at its core, currently using the Singer framework to enable replication of data in a reliable manner with features like schema validation, incremental syncs, and an ecosystem with hundreds of connectors that’s growing everyday. Also since the Singer framework has no intrinsic directionality, its also a perfect tool for reverse ETL use cases too.
Transformation: ELT needs a transform step and dbt has set itself as the recent standard for data transformations in SQL so Meltano has support for dbt as a plugin. The integration allows for better communicate between EL and T while also making it increasingly easy to get started.
Pipelines as code: Gone are the days of editing production workloads by clicking around a UI without code reviews or testing, Meltano allows you to define pipelines as code which can be deployed to production consistently using CI pipelines.
Plugin architecture: In order for your team be agile enough to quickly adopt new open source tools for testing (orchestration, deployment, data quality testing, observability, alerting, etc.) you need a tool like Meltano with a plugin architecture to support the stack you choose. Meltano makes it easy to add cutting edge tools to the stack as soon as they become available.
Environments: To enable teams to move fast with confidence, Meltano has a builtin environments features to make it easy to run your pipelines in isolated non-production environments. These are commonly set up to be used for local development along with CI pipelines for automated pipeline testing.
And a lot more…
There’s a new level of value and insights that teams are extracting from their data but they’re finding out that it’s only possible with the right tooling and practices in place. DataOps is the future and using Meltano will enable everyone to realize the full potential of their data!
Ready to make the switch?
Try Meltano today. You can get started in just a few simple commands.