Here at Meltano we have our own internal project which processes data for MeltanoHub and internal metric analysis. Recently we have been working on migrating our GitLab CI-based orchestration to using self-managed Airflow on Kubernetes. We are firm believers in the Open Source data ecosystem and want to make it as easy as possible to deploy and use Meltano using other Open Source technologies. By developing Infrastructure as Code (IaC) resources to support our own use cases, we aim to also accelerate your own journey to a production deployment by sharing our work and publishing our templates for wider use and adaptation. What follows is a description of our first-pass architecture, complete with deployable Terraform modules, targeting AWS, and a Meltano Helm Chart.
High-level Architecture of our Meltano Deployment
In our blog post discussing how we’ll build the DataOps OS, we highlighted the Meltano Project as a declarative representation of your data stack. This abstraction enables us to follow IaC architecture best practices by modeling our deployment in two tiers; a base Infrastructure tier with our Meltano Project on top:


These are defined and deployed separately, offering two key advantages compared to one large deployment definition:
- The life-cycle of our infrastructure is very different from the life-cycle of our Project; in general our infrastructure will evolve much more slowly than our Project layer. As an example, once a database has been created (and especially with services like AWS RDS that offer features like automated patching of minor versions) we may not need to modify it again for several months. However our Project tier moves much faster than this. We want to support multiple deployments per day as the numbers of contributors and workloads grow. Separating Infrastructure from the Project then allows us to manage these life cycles independently.
- Adding a boundary between the Infrastructure and Project tiers affords us the opportunity to begin to define an interface, facilitating reusability. Context passed from the infrastructure tier onto the Project about the resources available for use can (over time) be standardized, meaning that any infrastructure that satisfies those resources (on any hosting platform) can support a single Project definition. This encourages reusability, increases application tier portability and lowers the barrier to entry for experienced Project developers approaching new hosting environments.
These advantages directly contribute to our DataOps OS vision as we can bring version control, end-to-end testing, and isolated environments to the Project all while having it work more intelligently with the underlying infrastructure.
So what did we build?
Meltano Infrastructure Tier
As the base layer of our 2 tier architecture, we went for the Elastic Kubernetes Service (EKS) from AWS, leveraging managed ancillary services such as the Relational Database Service (RDS) for our Meltano and Airflow databases, the Elastic File System (EFS) service for log files and the Elastic Container Registry (ECR) service for storing and delivering Docker images to our cluster.

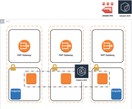
These specifics are not as important as the core technology choice; Kubernetes. We settled on Kubernetes as the foundation of our stack for several reasons:
- Kubernetes is Open Source, accessible to those self-hosting (including for local development) and is broadly available on many platforms with varying degrees of managed service offerings (like EKS on AWS).
- Kubernetes (and Helm, a tool for defining and deploying Kubernetes resources as Applications) have a rich and fast-growing ecosystem of Open Source ‘Charts’ (application descriptions) that we can leverage to avoid ‘reinventing the wheel’. In particular, our Project benefits from the robust Airflow Helm Chart maintained by The Apache Software Foundation (thank you!).
- Kubernetes scales gracefully, readily supporting workloads from small/medium to exceptionally large. For very small projects (especially those only requiring ELT) there may be more convenient options, however for most organisations that rely on data processing for business-critical functions, Kubernetes is tried and tested.
Check out the Terraform module, and let us know what you think in the #infra-deployment channel in the Meltano Slack workspace!
Meltano Project Tier
Right now our Project relies on just 2 applications: Meltano and Airflow. These are deployed as Helm Charts onto our EKS managed Kubernetes cluster, with Terraform doing the work to inject context output from our Infrastructure deployment (more on that in the Interface section below). An overview of the Kubernetes Pods created is as follows:

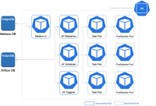
This simple setup leverages Airflow and both the Kubernetes Executor and KubernetesPodOperator for executing Tasks in our DAGs. What does that actually mean? Why use both the Kubernetes Executor and the KubernetesPodOperator? For a few reasons:
- The Kubernetes Executor (as opposed to the Celery, Dask or Local executors) is a great choice because we are deploying to Kubernetes. With the Kubernetes Executor, each task launches as a Pod in our Namespace, and exits once it completes. This is not only convenient, it offers simple scalability benefits by relying on Kubernetes cluster scaling mechanisms to grow the entire cluster rather than adding and managing long-lived Celery workers.
- The KubernetesPodOperator provides us runtime isolation; each Task gets a second Pod (in addition to the Airflow Task instance Pod) that can reference any arbitrary Docker container and arguments. Whilst this may seem wasteful at first glance (why not just use the container provided by Airflow to run our Task?), this approach has two important benefits:
- Our Airflow and Task environments are kept completely separated; we do not have to manage the dependency trees of both Airflow and our own plugins and tools.
- We get fine-grained control over the Pod definitions of our individual Tasks; meaning we can allocate more resources to some Tasks (say a high-volume database to warehouse ELT task) and less to others (say a regular SaaS sync ELT).
Check out the Meltano Helm Chart, and our Terraform module for deploying both Meltano and Airflow, and let us know what you think in the #infra-deployment channel in the Meltano slack workspace!
The Meltano ‘Interface’
Lastly, it is worth talking briefly about the interface between our Project and Infrastructure tiers. In our own Project we use AWS Systems Manager (previously known as SSM) to persist the outputs of our Infrastructure tier and Terraform to retrieve and inject them into `values.yaml` files as inputs to our Meltano and Airflow Helm Charts. Looking at that persisted object gives us some idea of what a formalised interface could look like:

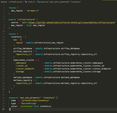
Those familiar with Terraform will spot what is happening here, but the gist is that we are capturing the outputs of our “infrastructure” module, formatting them as an object in a local variable called “inventory” and persisting that inventory as a JSON-formatted secret string in AWS parameter store. This means we have a simple JSON payload with all the details required by our Project Terraform module to be deployed! Huzzah! Over in our Meltano Project we retrieve this from Systems Manager and pass the individual values into the Kubernetes/Meltano Terraform module for injection into the relevant values.yaml files:
Our intention is that this ‘interface’ will become a part of Meltano, allowing you to store and reference resources that exist “in the real world” but that are not directly managed by Meltano, for use during deployment and as configuration for your plugins. Think of this as ‘sources’ from the dbt world, or the ‘inventory’ files from the Ansible ecosystem.

Thanks for taking the time to read this through. If you like what you see and want to help us build it, come join our community on GitHub! We’d love to have you as a contributor to the project or, if you’re interested in working on Meltano full-time, through one of our several open roles.