Now more than ever, companies rely on data to empower their teams, better serve customers, and make informed business decisions. While on-premises and hybrid data environments once reigned supreme, newer multi-cloud approaches have gained immense popularity. That’s forced many organizations to reconsider how they collect and process data.
Extract, transform, load (ETL) became the preeminent methodology for data ingest, and has been leveraged industry-wide. It’s ideal for aggregating and managing data within resource-constrained companies.
Fast-forward a decade later, and the Extract, load, transform (ELT) methodology began gaining popularity. It’s seen as a modernized approach that reorders how teams procedurally handle incoming data. ELT also adapts well to newer workflows, especially as processes shift over time.
These ingestion methods form a critical segment of the data pipeline and dictate how companies harness data from start to finish and impact cleansing, automation, modeling, and reporting. Naturally, none of this is possible unless data is gathered reliably.
In this article, you’ll assess the various strengths and weaknesses of each ingestion method. By comparing data collection concerns, integration and tool support, data load times, and the transformation process, you’ll learn about the pros and cons of both methods and why ELT is ultimately preferred.
What is ETL?
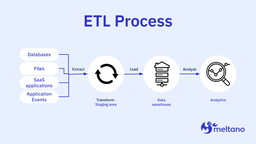
ETL first focuses on data sourcing from a number of locations outside your organization including databases, applications, monitoring tools, and emails. It’s the extraction process’s role to comb through these sources and ingest what it can.
ETL leans on automation to quickly ingest information once it’s deemed viable. Manual searching and vetting would take far too long and is more prone to error, which is why automation is preferred.
Transformation occurs next and involves organizing or formatting the data into specified styles.
Finally, ingested data transitions downstream to a data warehouse in the loading stage.
Note that this warehouse differs from a data lake, which commonly houses raw data catered to data scientists.
These stages also exist within ELT, but there are some core differences that will be addressed later in this article.
Data Collection and Compliance Concerns in ETL
In ETL, both extraction and transformation are tightly coupled since they precede loading. Transformations are purpose-built for specific workflows and data analysis procedures, making them bespoke. This specialization impacts the extraction stage by introducing more dependencies into the equation.
Increased complexities make it harder to scale and add data sources over time. As your files, application suite, and database grow, this can be problematic. Changes to upstream schemas must be reflected in the codebase, and those updates take time to complete.
To meet compliance concerns, proactive encryption and hashing are essential prior to loading. This occurs when the data is processed and an automated parser helps pick out PII or other sensitive information. This is critical across industries in which consumer privacy is paramount.
ETL Integration and Tooling Support
Because ETL is a longstanding process, many vendors, both large and small, have created tools and integrations to support it. These often incorporate some form of automation to make ETL more efficient at all stages, especially the first two, since they’re arguably the most involved. Faster loading is also desirable for teams with large quantities of data.
ETL platforms are designed to integrate with popular data sources and destinations. These might include household names like PostgreSQL, MySQL, SQL Server, Amazon Redshift, Tableau, or Teradata. Because data comes in different formats, depending on the use case, it’s important for tools to support emails, PDFs, XML, and JSON.
Different platforms will support varying numbers of vendors which determines how universal or targeted their solutions are. For example, you might have to use Tableau if a tool you’re fixated on supports it exclusively. Choosing something useful will require a deep look into your technology stacks and goals.
Unfortunately, the dated nature of ETL has geared it more towards on-premises or hybrid environments. Newer solutions like ELT are better suited for cloud deployments because of their scalability and integration support.
ETL Transformation Processes
Extraction and transformation are tightly integrated, which means transformations to ETL data happen very quickly as data flows inward. Your solution code will determine how those transformations take place. Raw data, or data without clear structure, is translated into data models, which deliver more value to analysts.
However, these models and general goals downstream can change frequently and the transformation is in a constant state of flux. Any alterations further down the pipeline require coding updates at the transformation stage; otherwise, the data won’t fulfill its purpose.
This requires ongoing maintenance. Teams must remain vigilant to avoid any transformation stoppages, which can trigger downtime.
ETL Data Load Times
By virtue of having loading last in the pipeline, data load times take longer within ETL systems. That, alongside any coding changes common throughout transformation, can delay loading into data warehouses.
There are two ways in which data is loaded: fully or incrementally.
A full load entails a complete data dump the first time that data is loaded into a warehouse. This is a sweeping step, and often one that precedes changes later on. These small additions are called incremental loads.
Payloads are more manageable overall, and changes to the data warehouse are loaded at predetermined time intervals. This ensures a more measured approach to loading. You can either stream small data volumes continuously or add new data in batches. The latter is best for larger amounts of data.
The full load is by far the most time-consuming portion of the loading process, but isn’t performed very frequently.
Incremental loading introduces complexity and is more challenging to do correctly. It requires more verification of fields, rows, and schemas, which can lengthen the overall process.

Advantages of ETL
For companies with limited resources (compute, storage, etc.), ETL can be transformative thanks to its frugality in resource consumption. Transformation processes act as a bottleneck to loading and ensure that smaller data quantities are transferred. Larger data dumps might otherwise require more CPU power, space, or bandwidth.
While ETL’s customized nature can be complex, it may also act as an advantage. Having a tailored set of data processes for unique needs is preferable to a one-size-fits-all alternative. Just make sure that your use cases won’t change dramatically over time.
ETL is also great for data governance and compliance. Data is usable and consistent after processing. Team members across departments can harness it for business purposes, and the addition of business intelligence (BI) tools can help rapidly generate insights. Your data will also be secure and have integrity throughout its existence.
Disadvantages of ETL
The main issues with ETL are maintenance, complexity, and expense. Maintaining your pipeline will require frequent code adjustment, occasional service restoration, and modeling changes.
Because ETL is customized, putting a pipeline into place is generally more costly. It takes additional time and effort, and may require outside intervention. You’ll also need a dedicated engineering team to oversee the pipeline throughout its lifecycle.
Loading times can suffer based on upstream complexity or outages, and the relative rigidity of ETL in respect to adding data sources can undermine its scalability. This can impact your ability to pair it with full-cloud deployments.
Can You Still Use ETL for Certain Use Cases?
ETL is ideal for privacy-centric data applications where anonymization and security are key. Organizations in the healthcare, government, and finance industries can benefit since they’re most often subject to compliance regulations, like HIPAA or GDPR.
You can also use ETL for destinations that require specific data formats. Transformation helps achieve this prior to loading, and prevents any wrinkles stemming from incompatibility.
Additionally, you can use ETL to introduce BI tools to your stack, building ML algorithms, or creating site-search tooling.
What is ELT?
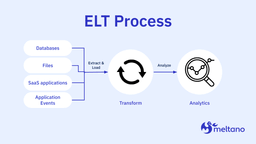
In contrast to ETL, the ELT methodology places the data loading stage in the middle of the process. This means that you’re taking raw, ingested data and directly adding it into our data warehouse or data lake.
The latter is included here because the data remains untouched prior to transformation.
It’s incumbent upon data scientists to determine a purpose for the data. ELT data that’s loaded is not considered “in use.” It’s also unstructured and unfiltered.
This allows for consequence-free modeling changes (relatively speaking) and lower schema sensitivity. The data workflow is shorter under ELT than ETL and features the following steps:
- Data source identification
- Automated extraction and loading
- Determine analytical and project goals
- Create data models via transformations
- Extract insights via analysis
Extracting and loading are independent from transformation. It’s important to note that while transformation attempts may fail, these failures simply cannot interfere with data loading. The workflow is more reliable as a result. Downtime concerns are reduced and this decoupling removes the bespoke element seen with ETL.
Since transformations occur in the warehouse or lake, there’s no need for scripting or other mechanisms to facilitate transformations. These transformations are best left to SQL, which is commonly known amongst data analysts.
Simply put, ELT improves upon many workflows previously encountered under the ETL umbrella, and especially so for cloud-based environments. Data collection is wide-ranging due to the cloud’s vast data-residency footprint (data is spread across many diverse sources), and it’s generally easier to ingest targeted information.
Advantages of ELT
Generally speaking, ELT does a few things very well, giving it a few clear advantages over ETL thanks to the inherent efficiency, reliability and scalability built into the flow. Let’s look at four key points that make ELT the superior process between the two.
#1: Less Destructive
You don’t want that to be a one-time or destructive process that can’t be repeated or that can’t be iterated upon.
#2: Repeatable
The transformation is where you want to apply your business logic you’re cleansing. And the important thing to think about is that transforms your business logic and your cleansing is going to improve constantly.
#3: Fewer Errors and Duplicate Work
When you do the transformation in the middle, then you’re in, you’re imposing your business logic on the data. While it’s in flight, as your business laws changes, you have no way to rerun what you ran at that point in time. You’re also going to have a lot more failures.
#4: Collaborative and Cost Effective
What is helpful about ELT is that you can have a kind of virtuous downstream cycle. The example being, I extract and load transform and publish. But my teammate also needs to extract from me and they can have the same process and so on and so on and so on. So you can have a core team doing ELT. They can also have subscribing teams which can have subscribing teams and so on and so on. The benefit of this ETL process here is that they have an official record of whatever we published on that day. You are able to restate everything to your downstream consumer who will have some record of what I published on that day. And that’s one of the reasons why we have a separate EL step vs including the transformation in with the replication.
Disadvantages of ELT
However, no methodology is perfect. Because ELT is cloud-based in most instances, it’s not ideal for on-premises deployments. It’s important to choose your approach based on your infrastructure.
The source friendliness of ELT can be a double-edged sword. While incorporating data from multiple sources is useful, moving those massive quantities of data can impose added security risks. Teams must be extra vigilant to prevent corrupted or compromised data from being loaded. Accordingly, ensuring strong compliance can take some additional effort, due to the additional moving parts on the sourcing side.
You must also watch out for excess resource consumption. Managing a multitude of platforms across multiple vendors can incur large costs, or lend itself to poor resource optimization. How exactly do you handle explosive growth over time? Answering questions like these is essential to extracting maximum value from ELT methods.
When to use the ELT process
Because of ELT’s unique features and advantages, it is superior to ETL as a data processing protocol in a variety of use scenarios and projects. But when would ETL benefit you the most?
Here are a few scenarios when ELT would work best for you:
- You run a small to medium-sized enterprise: Let’s start with the most obvious scenario that has to do with one of ELT’s key advantages: cost. The truth is that ETL, despite all its advantages, can be too costly of a solution for organizations that don’t have enough resources to operate a maintenance-heavy system. By comparison, ELT is a much more affordable solution that can be more suitable for small or medium-sized organizations that don’t have the resources or need for a costly solution.
- You need to process a large data set, quickly: Due to its inherent scalable cloud computing abilities, ELT is more capable at loading and processing large data sets. By comparison, ETL is best suited for smaller data chunks and can be more sensitive to the data quality and formatting due to the limitation of the staging transformation environment.
- You need to keep all your old data at hand: Processing your data using ELT means that once it reaches your data warehouse or storage and gets processed, it will stay there indefinitely — as long as the storage capacity allows it. This can be a crucial factor for organizations that prefer to keep all their data in one place, including its unprocessed raw form. With ELT, you will always be able to access your old data in case you need to use it at any point in the future.
In contrast to many ETL solutions, ELT is cloud-based and does not require as much human input for updates and maintenance.
Conclusion
Embracing multiple cloud vendors for sprawling workloads has become both essential and preferred over on-premises alternatives. Accordingly, the data stemming from those sources deserves a modern approach to management, which is why ELT has become the prominent method. Its simplicity, cost-effectiveness, and inclusivity make it attractive for large data sets.
Not every ELT solution is built equally. Meltano offers an open-source platform for data management and DataOps. It’s self-hosted, CLI-first, debuggable, and extensible, ideal for power users who favor control and functionality without being overwhelmed by complexity.
Their pipelines-as-code approach offers unique benefits, including:
- Version Control
- Containerization
- Continuous deployment
- Easy pipeline development and testing
If you want a tool that helps you run a robust ELT pipeline, follow along with their Getting Started Guide to learn more.
Guest written by, Tyler Charboneau. Thanks Tyler!