Your CTO just called, he discovered plain text emails inside one dashboard and is raging, apparently, a list got leaked out to one of your customers.
These were hidden in a “comment column” you imported.
Sounds familiar?
Now you’re stuck with all the hassle, removing these data pieces, conducting a security audit, and spending lots of time not doing your actual job: delivering more insights.
We know you probably care deeply about security. We do so as well, so we made Meltano great at dealing with anonymizing and deleting data inside extract & load processes.
We’re going to share the three different ways you can use Meltano to take care of your data security needs to mask, hash, or delete PII data.
Data security should be easy, natural, versioned, & auditable for the data engineer.
Data engineers should focus on delivering insights and data, not on hunting down free text fields or data privacy issues.
Yet data security is already a prime concern for almost every company.
So to make the data engineering work fast while also improving data security, an extract and load tool should:
- Make removing possibly problematic fields as easy as possible -ideally in one simple line
- Integrate it into the data engineering flow, versioned, auditable, and testable.
- Remove possibly problematic data pieces even before they land inside the central data storage, be that a data lake or a data warehouse.
Meltano is built to do just that. It has a feature called “inline data mapping” that comes in two flavors and allows for all of the above. Let us explore three different ways this feature makes your privacy problems no problems at all!
The three different approaches are masking, hashing, and deleting.
Most data privacy problems happen because possibly private data lands in a central data warehouse in the first place. That’s usually hard to avoid because sometimes we don’t know what sensitive data is, or we don’t have a way to “not retrieve” it along with the information we want.
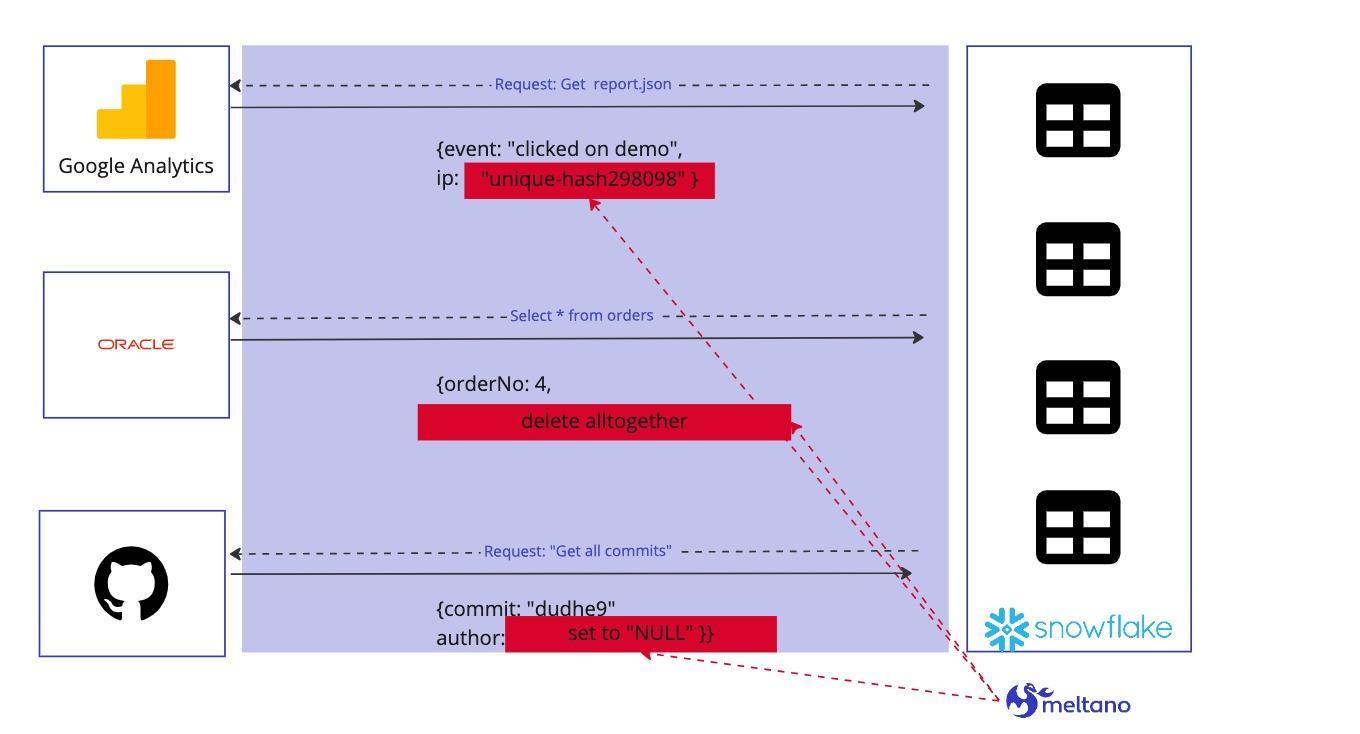
Here are three typical examples:
- We want to be able to tell apart different users from Google Analytics, the way to do that is to get parts of the IP.
- We want to pull order data from the production database, and we opt to run a “select *” to make things easier.
- We want to retrieve data from an API e.g. the GitHub API. However, it also delivers PII data.
What we’re doing at Meltano is allowing you to do small mappings to take care of all of these cases, to remove data fields you don’t want, to replace them with other non-sensitive values, or to hash them in a unique way.
Note: Since “inline stream maps” are actually a part of the Singer specification, you can use all of the above without using Meltano. Meltano just makes it a lot easier.
Case 1: Hashing Google Analytics IPs
When ingesting certain Google Analytics data pieces into a central data warehouse, we usually don’t need to know their exact IP address. All we usually care about is that they are unique.
That’s where “hashes” come into play. A hash is just as unique as the IP address with the catch that you cannot identify the person behind the hash because it is irreversible.
If you hash IP addresses, you’re still able to get unique counts and everything you probably are looking for, without risking the privacy of the people behind these IPs.
In this case, we can add a separate step between the extract => load, and the extract => map => load step. A possible configuration looks like this:
plugins:
mappers:
- name: meltano-map-transformer
variant: meltano
pip_url: git+https://github.com/MeltanoLabs/meltano-map-transform.git@v0.0.4
mappings:
- name: hide-ips
config:
stream_maps:
gcp_ips:
ipv4: null
ipv6: nullid: "md5(record.get('ipv4', record.get('ipv6')))"Since you’re doing this inside our extract & load process that runs on Meltano as well, the IP addresses never touch your data warehouse. They get deleted on the fly.
You could even add tests to make sure no such data ever goes into your data warehouse, no matter what people change in the process. We for instance are running tests for all our ingestion pipelines at least once a day, or more often:
Case 2: Select * from a database.
The Meltano taps & targets work great when it comes to moving data from database to database.
If you’re taking a production postgres database and moving this data into your Snowflake account, Meltano can automatically detect schema changes like added columns and propagate them to your snowflake account.
To get the benefits of a “get everything” request, while still deleting PII columns altogether you can use mappers as well.
For this case, we usually won’t even need to add the step from above, because most database taps already have inline stream map support built in. In that case, we simply need to configure out extract step with our mapping:
…
- name: tap-postgres
config:
[...]
stream_maps:
orders: #work with the orders table
id: "order_id" #rename id to order_id to separate from customer id
cust_email: null
cust_name: null # null email and name of customer, not needed here.
add_comments: null # don't pull in free text comments...Case 3: API/database returns too much data.
The third case is that you extract data, and simply get too much, including PII.
A typical example includes typical APIs, or database columns that have “blobs” inside them. In that case, you can still use a mapper to go into your nested object, whether it comes from a database or an API and for instance set the according values to NULL.
We’re providing a very similar example of this in action inside our tutorial.
mappers:
- name: transform-field
variant: transferwise
pip_url: pipelinewise-transform-field
executable: transform-field
mappings:
- name: hide-github-mails
config:
transformations:
- field_id: "commit"
tap_stream_name: "commits"
field_paths: ["author/email", "committer/email"]
type: "SET-NULL"This will take a blob of data returned from the GitHub API that looks like this: …
{"sha": "409bdd601e0531833665f538bccecd0f69e101c0",
"url": "https://api.github.com/repos/sbalnojan/meltano-lightdash/commits/409bdd601e0531833665f538bccecd0f69e101c0",
commit: {author: {email: "my@mail.com"}, committer: {email: "my@email.com"}}
}And turn it into this:
{"sha": "409bdd601e0531833665f538bccecd0f69e101c0",
"url": "https://api.github.com/repos/sbalnojan/meltano-lightdash/commits/409bdd601e0531833665f538bccecd0f69e101c0"
commit: {author: {email: NULL }, committer: {email: NULL }}
}Now feel free to try out Meltano to speed up your data engineering tasks while keeping your customers’ data safe.