It’s 2023, and dbt, the default option for transforming our data, is already seven years old, just two years shy of Apache Spark. That’s almost an eternity in the fast-moving world of data.
Fun anecdote: the term “data lake” was introduced by James Dixon, the then CTO of Pentaho, one of the leading legacy ETL tools, in 2010.
And while the data lake has slowly evolved over the years to match today’s world, ETL, the Extract-Transform-Load pattern, hasn’t evolved but rather is being replaced. Replaced by a different pattern called ELT: Extract-Load-Transform.
dbt stands for the emergence of ELT as a default choice for many data engineers.
This guide is for everyone who has already felt the urge to switch from ETL and is curious about what ELT really is about. It is also for you if you’re a data engineer who wants to start a new project – because then ELT should be your default option as well.
dbt stands for the emergence of ELT as a default choice for data engineers.
But there’s one big catch, as Maui says in the Disney movie Moana, “To know where you’re going, you need to know where you come from.”
There is so much legacy baggage, colossal marketing budgets still broadcasting legacy ETL marketing messaging, and assumptions long invalidated that you won’t get to a good solution for you and your company without understanding the ETL history first.
Legacy ETL baggage still clouds all our vision. You need to understand ETL to understand why you’re better off with ELT and how to use it properly.
This guide will walk you through the What and Why in detail:
- What is ELT vs. ETL
- What’s the difference?
- Benefits of ELT
- Why did ETL emerge if ELT is much better?
- “ELT” and “ETL” tools
- The main pain points of ETL
- Key ETL vs. ELT lessons
What is ELT
Neither ELT nor ETL describes a tool per se.
Both ELT and ETL are architecture patterns for organizing data pipelines, getting data from various source systems, turning them into information, and delivering them to an end-user.
Neither ELT nor ETL describes a tool. Both ELT and ETL are architecture patterns for organizing data pipelines.

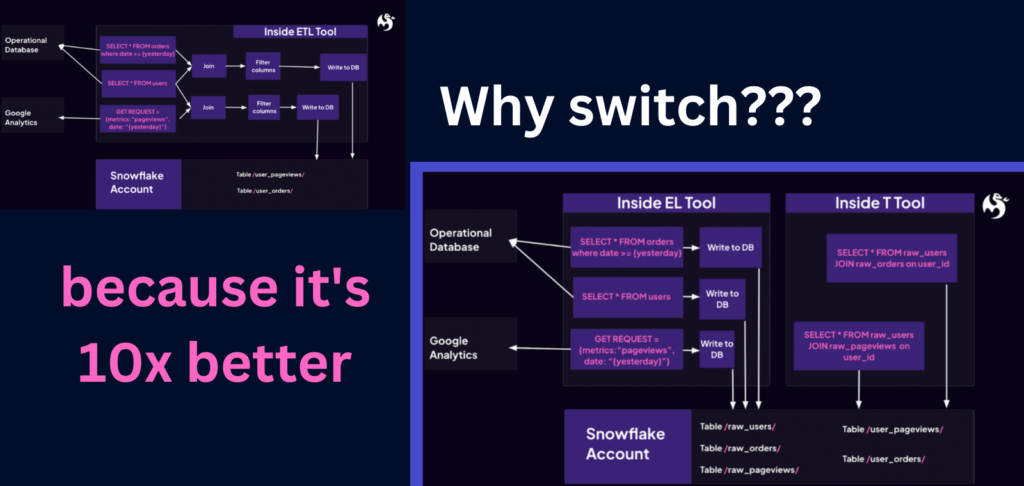
Analytics is all about bringing data together, data from different sources. The graphic above describes the analytics ETL workflow turning raw data into information. The typical three steps in analytics work are
Extract: Data is captured in hundreds of tools. Google Analytics captures website visits, your backend database captures orders, Salesforce holds your company’s customer contact details, and REST APIs, in general, are all over the place capturing and delivering data. Extracting data means retrieving this data from all of these different sources (but not YET putting it someplace else.)
Transform: Data from multiple sources needs to be unified somehow. Your customer IDs in Salesforce might not match your Backend DB; Google Analytics might send too much data. Transformation is the step where you take data, clean it up, and combine it to create meaning from the raw data.
Load: Your meaningful data needs to be somewhere suitable for analytical workloads like a data warehouse. Loading this meaningful data into your data warehouse is called the load step of the ETL and ELT architecture patterns.
ETL and ELT are architecture patterns which means they can be implemented with one or multiple tools, not just “one ETL/ ELT tool.” Let’s look at two examples of this.
The key idea of the ETL pattern is to take lots of data from source systems, then transform them in any way before putting them into a target system like a data warehouse.
An example of a typical ETL data pipeline

For the users_orders table (ETL):
- Get all users from the operational system
- Get the orders from yesterday from the operational system, and join them together to create a list of user orders.
- Filter out everything irrelevant, cast data types, rename, etc.
- Write everything into Snowflake.
For the users_pageviews table (ETL), we’re starting in parallel:
- Get the pageviews from yesterday from Google Analytics, and join them together to create a list of pageviews by users.
- Filter out everything irrelevant,
- Write everything into Snowflake
This pattern has a small footprint on the source and the target data warehouse. The ETL tool gets batches from the source database, joins them in memory, and then filters down to the column we need, again in memory. Finally, the ETL tool writes the joined user_order and our second table into our data warehouse Snowflake.
An ELT example
ELT exchanges the loading and transforming of data. The ELT architecture pattern tells you to extract and load everything into a target system and then do the transformation inside the target system, e.g., your data warehouse.
Let’s turn the ETL pipeline from above into an ELT pipeline. Our goal still is to create two tables, one user_order table and one user_pageview table.

For the raw data (EL):
- Get all users from the operational system
- Get yesterday’s orders from the operational system
- Get yesterday’s pageviews from Google Analytics
- Write all three tables into the data warehouse.
For the transformed data (T):
- Get the orders and users from the data warehouse, and join them together to create a list of user orders.
- Get the pageviews and users from the data warehouse, and join them together to create a list of user pageviews.
Sounds different. The list above is grouped into an “extract & load raw data” and a “transform data” step on purpose. Both steps in themselves are much simpler than before. The extract and load step, the “raw data” step (EL), is a simply copy-and-paste process.
On ELT, individual steps themselves are much simpler than in ETL.
The “transformation step” (T) is defined as a SQL statement within our T tool and then pushed into our target data warehouse. The process is thin on the memory of our EL & T tools.
This grouping is only possible with an ELT pattern. The ETL pattern by choice throws both steps into one bucket and thus makes them more complex.
Note: This example uses Snowflake and an SQL-powered transformation tool like dbt. But there are many more transformation tools and data warehouses out there.
What’s the difference in outcome?
The table below summarizes the differences in our approaches. With ELT, we use more tools but simpler ones. We get more raw data tables and can utilize the computation power of our data warehouse.
| ETL | ELT | |
| Data tables in the data warehouse | User_orders (transformed), user_pageviews (transformed) | Users (raw),Orders (raw), Pageviews (raw), User_orders (transformed),Users_pageviews (transformed) |
| Most computation | Inside ETL memory | Inside data warehouse |
| Number of tools in use | 1 | 2 |
Benefits of ELT in this example
This difference has several benefits with no downsides. In our example, we have the following ones:
- Performance: In the ELT workflow, the computation is performed on the data warehouse. Data warehouses are made for such types of computations and, as such, are more performant and cheaper than the in-memory ETL process.
- Reduced complexity: A couple of copy steps and SQL statements. If a new data engineer joins the team tomorrow, he could add a new table within an hour.
- Future proof: If we need to provide an order_pageviews table tomorrow, we can do so without retrieving new data.
- More flexible: If we need to add more columns to our user_orders table today, we can do so without retrieving new data.
Why did ETL emerge if ELT seems so much better?
“ELT has emerged as a paradigm for how to manage information flows in a modern data warehouse.” (“What is ELT,” docs.getdbt.com)
Even though ELT is the default choice for most data engineers, ETL is still everywhere. And that has a historical reason that doesn’t hold true anymore.
Back in 2005-2006, when the ETL tool “Pentaho Data Integration” was open-sourced and bought by Pentaho, there was no Apache Spark, there was no AWS Redshift and no Snowflake.
Storage was still relatively expensive, roughly 30 times as expensive as today: 406$ /TB compared to 14.30$ per TB today. Databases were primarily made for storage and retrieval of stored datasets, less for computation on top of these datasets.
Expensive storage meant people didn’t want to store a lot of data. Databases didn’t do computations well, so people opted not to do these heavy computations inside the database.
Expensive storage and low performance on computations that’s precisely the problems ETL tools solved. They implemented the ETL pattern, sourced lots of raw data, did computations in memory, and then stored the relatively small resulting dataset inside the database. The data warehouse, in turn, was great at storing and reading data—a perfect match.
But today, things look very different.
| Today | When ETL emerged (2005+) | |
| Cost of data storage | 14.30$ | 406$ |
| Database computation ability | All data warehouses are optimised for heavy computation. | basic |
| Computation tools on top of databases | A plethora of Apache Spark, dbt, Jupyter notebooks, Pandas,… | Very limited |
ELT and ETL tools
Now we’re left with a mumbo jumbo of terms: “data integration,” “data movement tool,” “ETL tool,” “ELT paradigm,” and many more. There are, however, only a few things you truly need to know to make a good decision on tooling:
ELT tools: Tools called “ELT” support the ELT architecture pattern. That means they usually do the “EL” part of ELT. dbt, on the other side, is a tool that only does the “T” part and stands firmly behind this pattern.
ETL tools: Tools called “ETL” support the ETL architecture pattern. That also means they allow you to implement it using their tool. They are made to make it easy to modify data after extracting it from the source and before loading it into a data warehouse.
Warning: You could also do the EL part of ELT with an ETL tool. But we advise against this tool choice. The ETL-supporting tools are too heavy to do just the EL tasks and are easily misused even with good intentions. Using ETL tools as EL tools inside an ELT pattern will erode the benefits of the ELT pattern and revert to an ETL pattern. (Sorry for the acronym avalanche!)
CDP tools: Tools that use the term “customer data platform” as their primary messaging usually do not fit into the ELT vs. ETL pattern. Although they can be used as EL or ETL tools, they focus on three things:
- Systems carrying customer data,
- Near real-time data movement
- Moving data beyond a data warehouse into other systems.
Data integration & Data movement: Tools that refer to data integration or movement can be in any of the categories mentioned above.
Here’s an example overview of these tools.
| Product | E, L, T, ETL, CDP? | Description | Open source |
| dbt | T of ELT | It is a workflow using templated SQL to transform your data | (v) |
| Meltano | EL of ELT | Is a CLI + YAML-based workflow for your EL | (v) |
| Other modern EL tools | EL of ELT | Mostly GUI based | (v and x) |
| RudderStack | CDP | Collects and activates customer data throughout your warehouse, website, apps. | (v/x) |
- Lesson 1: If you want to implement ELT, choose one tool for EL and one for T.
- Lesson 2: Choose a true EL (T) tool for the job.
- Lesson 3: Choose tools, both for T and EL, that specifically state they are built to be used in such a way.
But what exactly are the pains of ETL?
Pains of ETL or how to spot the time for a switch
The benefits in the example above are the flip sides of the pains you might experience with ETL. Go through the following list. If 1-2 items on the list speak to you, you should look into a switch; an ELT pattern coupled with a good set of ELT tools will resolve these pains and strengthen your data team.
Don’t just think about the technical limitations you’re experiencing; human problems are often the most severe.
Lack of version control
ETL tools seldom provide version control. If you’re having trouble reproducing a change someone else did or restoring an old version of your pipeline, you’re experiencing this pain.
Your transformations feel “too complex”
ETL tools encourage you to put a lot of business logic into pretty little GUIs. Up to the point where the roof collapses over your head, and things become too complex. If new data engineers need months to understand your data pipelines, you’re likely feeling this pain.
You long for a test harness
Are you scared of pushing your changes into production? Then you’re missing a test harness. ETL tools usually provide only limited testing abilities. That’s mainly because the complexity of pipelines makes testing really complicated and thus challenging.
Your changeset breaks the production system
You changed a pipeline, tested it, and it still breaks in production. Then you need a staging system to test your changed pipeline in isolation but in a close-to-production environment before pushing it into production. ETL tools only have limited support for managing environments.
Your data team feels it cannot adopt DataOps
ETL tools produce complex pipelines by throwing EL and T together into one pot. It is hard to adapt the development of such complex pipelines to DataOps practices. Better start with more straightforward development tasks.
Data needs to be reloaded entirely
A significant change to one of your ETL pipelines will usually cause you to reload millions of rows of data to propagate the change through your ETL system, mainly if it contains aggregated historical data. The coupling of loading and transformation is a severe limitation of ETL that causes this.
Your data analysts would like to be included in the transformation process
Are your data analysts looking to be included in the data transformation process because they are unsure what comes out on the other end? Then your ETL tool is likely too technical and thus prohibiting your data analysts from participating.
Out-of-memory problems and “fat instances”
Are you running your ETL on massive memory instances? Are you paying much money for your ETL tool as a cloud service? That’s because all computations are performed in expensive memory and must happen synchronously. If you were ever surprised at your ETL tool bill, you probably felt pain.
Long-running ETL pipelines
Complex ETL pipelines need a prolonged time to finish because of hidden dependencies. If your hourly pipelines need more than an hour to finish, this will be painful for you.
Time to fix is measured in days
If your data pipelines break, are you measuring your time to fix in days rather than hours? ETL pipelines will always need you to retrieve data again, which usually takes a day or so. That isn’t too much fun for your “daily” dashboards.
Development of pipelines takes ages
To develop a new ETL process, you’ll need to hit the source system, again and again to ensure things work. To develop a new ELT process, you’ll first do the EL and then the T without touching the source system again. If you’ve ever been called by a system admin who doesn’t like you querying the backend DB repeatedly, then you felt this pain.
Situations that still require ETL
… do not exist.
At least not ETL in the sense of heavy ETL tools. The “Analytics Engineering Glossary” points out the possibility of good uses of ETL tools that we think are outdated, and you should solve them differently.
ETL for hashing PII before load
Some companies must change data before loading it into the data warehouse.
Two common examples are
- masking private information or
- removal of security-relevant data.
In this case, you should make an exception to a 100% ELT pattern. But instead of falling back on an ETL tool, the better option is to use EL tools that provide you with lightweight transformation capabilities like masking and removal without adding the heavy burden of 100% ETL patterns.
Many EL services can do this, as does Meltano.
CDPs
Tools like RudderStack or Segment support ETL-like patterns but cater to a different use case. The use case mainly connects customer-centric data and publishes it to multiple targets. In those cases, the ETL-like pattern used by CDP tools still can make sense.
ETL legacy baggage
The assumptions that ETL is based on are not valid anymore. ELT emerged as the debate winner.
But the market is still full of ETL. A lot of tools still try to get you to implement ETL. Your organization might still be on ETL.
Our recommendation is to stay away from ETL tools unless you have an excellent reason to. If your organization still uses ETL, then it is time to consider a switch.
In part 2, we will help you to plan your migration to ELT, but first, go through the list of pains and see for yourself whether you feel the pain.
Key Takeaways
- ELT should be the default option for any data engineer starting something new.
- Companies still on ETL should consider a switch.
- ELT and ETL are architecture patterns for data pipelines. ETL is usually implemented with one ETL or data integration tool; ELT is usually implemented with one EL and one T tool (e.g., dbt).
- ELT offers a lot of benefits with next to no downsides over ETL.
- ETL was created because storage on databases was expensive, and their computation powers were limited.
- Today, database storage is super cheap, and they are optimized for computing.
- Vendors still use the legacy ETL terminology to market their (both ETL and non-ETL) products; beware.